

[ad_1]

Credit score:
metamorworks/shutterstock.com
We’re excited to introduce our third visitor writer on this weblog sequence, Dan Kifer, Professor of Pc Science at Penn State. Dr. Kifer’s analysis spans many subjects associated to differential privateness and social information, and a choice of his work represents the state-of-the-art within the topic of this weblog put up: testing strategies for detecting differential privateness bugs. – Joseph Close to and David Darais
Within the final put up, we realized that it’s pretty simple to introduce bugs within the design and implementation of differentially personal algorithms. We additionally realized that it may be tough to seek out them. In truth, within the worst case, it’s mathematically unattainable to seek out all privateness bugs. So what’s the purpose of attempting, proper?
The excellent news is that almost all bugs are pretty simple to detect with a bit of little bit of experimentation. Anybody can do it, by following this three-step course of:
- Create a pair of datasets X and Y that differ on one individual.
- Establish an final result to give attention to.
- Present this final result is just too frequent or too rare when the enter is X in comparison with when it’s Y.
Surprisingly, that’s all it’s essential obtain fame and glory. On to the main points…
Pairs of Datasets
It’s our job to create two datasets X and Y that differ on one individual. Is that loads to ask? Sure, it’s. So let’s make them easy — it seems that many privateness bugs may be detected with tiny datasets. Allow us to contemplate the next utility.
We need to privately compute the common age of a gaggle of individuals. We all know the ages are between 0 and 120 (for the fortunate ones who have a good time their 121st birthday and past, we nonetheless document their ages as 120). We all know that the common age ought to subsequently be between 0 and 120. Which means that we should always have the ability to obtain ?-differential privateness by taking the common age and including Laplace noise with scale 120/? (don’t do that in apply, there are a lot better algorithms on the market). Right here is a few Julia code that does precisely this:
utilizing Distributions
private_avg(ages, epsilon) = sum(ages) / size(ages) + rand(Laplace(0, 200/epsilon))
Two traces of code! Certainly there are not any bugs right here! Let’s check it anyway. What are the best datasets X and Y we are able to create? Effectively, X may be empty, no folks in any respect. On this case, the ages array will merely be this: []. We are able to get hold of dataset Y by inserting one individual, say 120 years previous. The corresponding ages array might be [120]. What occurs if we name private_avg([120], 0.001)? We might get some unusual quantity like -22928.63670807794 (this isn’t a bug, it’s simply very noisy). If we had been working with dataset X, we as a substitute can be calling private_avg([], 0.001). What occurs right here? We’d get a protracted, scary error message as a result of our code divides by 0.
So, this can be a bug and is even exploitable. I might use a really small ? (say 0.0000000001) and ask for: (1) the differentially personal common age of all folks named Joe Close to with birthday 1900/01/01, (2) the differentially personal common age of all folks named Joe Close to with birthday 1900/01/02, and so forth. (all the way in which as much as 2021/04/31). The one time I wouldn’t get an error is when I’m utilizing the right birthday. Consequently, the software program system would assume I used a really small expenditure of privateness price range, however in actuality, I be taught precisely after I want to purchase a cake.
To summarize, quite simple pairs of datasets X and Y can be utilized to detect bugs. Search for bizarre conditions: an empty dataset, a dataset with an excessive worth, and so forth. In the event you let your creativity run wild, you might understand that generally you may’t cowl all attention-grabbing instances with only one pair of datasets. That’s okay. You possibly can create a number of pairs of datasets: X1 Y1, X2 Y2, X3 Y3, … the place every X in a pair differs from its corresponding Y by 1 individual’s information. We are able to run a bug discovering process for every of those pairs of datasets.
Outcomes to Concentrate on
Within the earlier instance, we centered on a particular final result, the error message, which at all times occurred when the enter dataset was X and by no means occurred when the enter dataset was Y.
In a extra basic setting, suppose we’re searching for differentially personal mechanisms. As a substitute of shopping for a brand-name mechanism, we’re tempted by the value of an inexpensive knock-off. Luckily, we are able to attempt it earlier than we purchase it. So, we create a pair of enter datasets X, Y that differ on one individual’s information. We run the mechanism a number of instances with X because the enter and depend what number of instances every output has occurred. We then make a fairly plot:
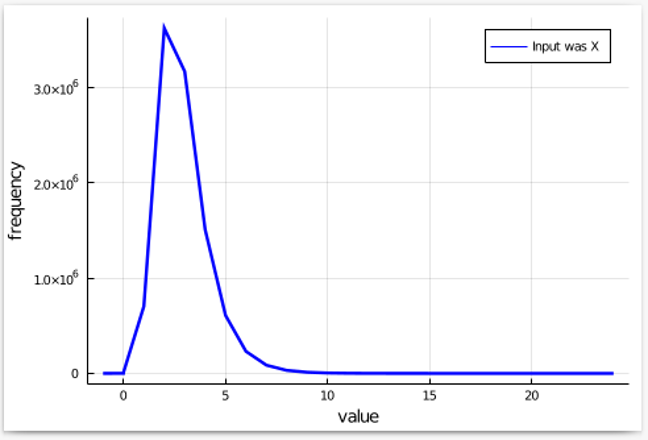
Since we might be doing the identical with Y because the enter, after which analyzing the issue by which one thing turns into extra frequent (or much less frequent), it’s higher to view the pure log of the frequencies. This converts multiplication by an element into addition or subtraction, which is simpler on the eyes. Omitting factors the place the frequency is 0, we get a plot that appears like this:
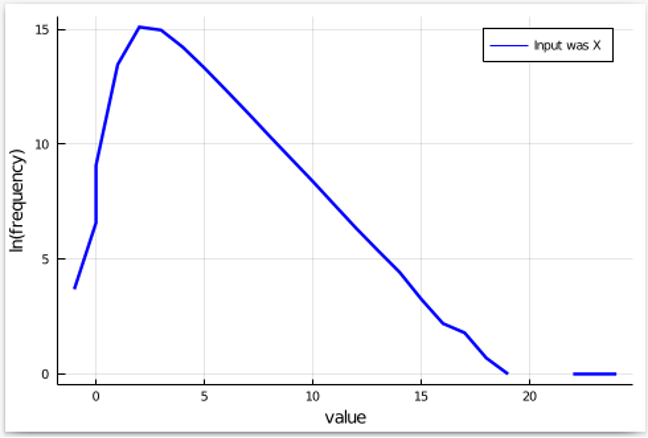
Subsequent, we all know that ?-differential privateness permits occasions to turn into exp(?) extra frequent (or much less frequent) as we swap inputs from X to Y. So, allow us to add these higher and decrease bands for our plot:
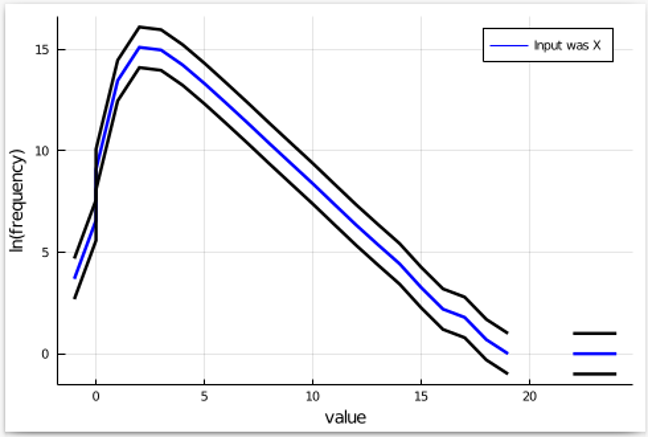
Lastly, we run the mechanism a number of instances with Y because the enter, depend the frequency of every output, and add it to this plot. If the mechanism satisfies ?-differential privateness, the plot for Y needs to be inside the black bands. Let’s see what occurs:
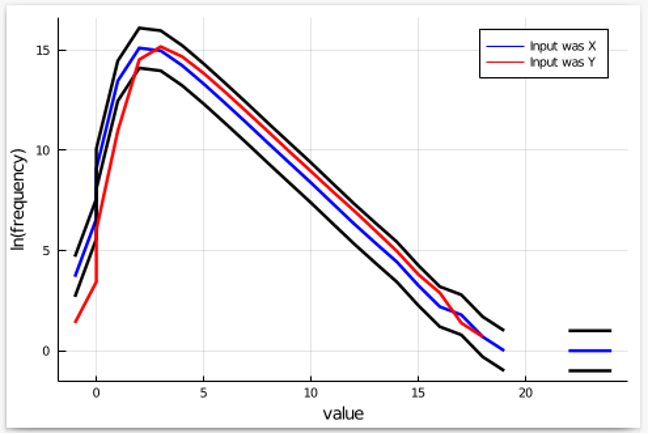
We see that outputs lower than 0 look like a lot much less frequent than they need to be. Therefore, the set of outcomes we needs to be specializing in is the set of outputs which might be 0 or much less. If we are able to show that such outputs are certainly too rare when Y is the enter, then we show that our low cost knock-off mechanism doesn’t have the claimed privateness stage.
Present the Consequence is Too Frequent or Too Rare
Now, it’s attainable that our observations within the earlier determine had been fully as a result of probability. So, now we have two choices: both we show mathematically that outputs lower than 0 are more likely if X is the enter in comparison with Y, or we are able to run statistical checks that may verify it. Each approaches are utilized in present instruments, a few of that are described subsequent.
Software program Instruments
We noticed that the final methodology for locating bugs in supposedly differentially personal applications consists of figuring out good pairs X, Y of enter datasets, figuring out outcomes to give attention to, after which exhibiting that these outcomes are too frequent/rare when X is the enter as a substitute of Y. All of this may be tedious, time-consuming, and in any other case tough. Luckily, there’s a long-standing joke that pc scientists are so lazy that they devise software program to do their work for them. There are fairly a couple of techniques now that may do a few of this work. StatDP and DP-Finder had been the primary to be invented — the dialogue on this weblog relies on the StatDP methodology. Since then, extra highly effective techniques have been developed: CheckDP, DiPC, and DPCheck — and this checklist continues to develop.
Coming Up Subsequent
This put up centered on superior testing strategies for detecting privateness bugs. One good thing about this strategy is that you could set up confidence that privateness is preserved by your program simply by observing its enter/output habits over a number of executions. Nevertheless, as the dimensions of the enter or output area will get massive, or the computation turns into costly to execute, the final strategy of testing enter/output habits turns into tougher to use. Within the subsequent put up we’ll talk about one other set of methods for attaining assurance that applications are freed from privateness bugs. These approaches make the most of program evaluation, which examines this system itself — not simply enter/output habits — and may give confidence in right implementation of privateness after only a single execution of this system, and even with out operating this system in any respect.
This put up is a part of a sequence on differential privateness. Be taught extra and browse all of the posts revealed up to now on the differential privateness weblog sequence web page in NIST’s Privateness Engineering Collaboration House.
[ad_2]
Source link







{kind=link}