

[ad_1]

Credit score:
metamorworks/shutterstock.com
In earlier posts we mentioned alternative ways to implement differential privateness, every of which provides some trade-off between privateness and utility. However what does “utility” imply, and the way do we all know we’re preserving it? To debate this subject, we’re delighted to introduce one other visitor creator in our weblog collection, Claire McKay Bowen, Lead Knowledge Scientist for Privateness and Knowledge Safety on the City Institute. Claire’s analysis focuses on assessing the standard of differentially non-public information synthesis strategies and science communication. In 2021, the Committee of Presidents of Statistical Societies recognized her as an rising chief in statistics for her technical contributions and management to statistics and the sphere of information privateness and confidentiality.
– Joseph Close to and David Darais
Being a privateness researcher, I’m typically requested, “How do you make sure that any publicly launched differentially non-public information or statistic will nonetheless produce legitimate outcomes? How do you stability this in opposition to the disclosure dangers or privateness wants?” Most individuals who ask these questions count on a one-size-fits-all utility metric that completely assesses the standard of any publicly, differentially non-public information or statistic. However, such a metric doesn’t exist generally.
As a substitute of in search of the final word utility metric, we should always ask ourselves, “Who’re the info practitioners or information customers, and what is going to they use the info and statistics for?” In different phrases, privateness researchers ought to seek the advice of and set up data-quality metrics based mostly on how different researchers, establishments, and authorities companies will use the info and statistics.
Nonetheless, figuring out which particular metrics to use is itself a whole analysis area. It’s unattainable to foretell all doable analyses that information customers would possibly implement and make sure the information will present legitimate outcomes for every of these analyses. This implies privateness researchers should have open discussions with information practitioners about which utility metrics are proper for evaluating the altered information high quality, as a result of each dataset and use for that information is exclusive.
Utility Metrics
To supply some steering, I’ll cowl a number of use circumstances of what utility metrics privateness researchers and information customers applied. Observe that these examples solely cowl just a few of many different sorts.
Abstract Statistics
Many privateness researchers will first look at the abstract statistics of the anonymized information as a fast and simple start line for assessing utility. Additionally, most information practitioners can simply perceive and interpret abstract statistics in comparison with different utility metrics. For instance, frequent abstract statistics measure how properly the launched information protect the counts, means, and correlations for every variable or mixture of variables. The privateness professional then reviews the gap between the unique and noisy outcomes. Sometimes, these distance measures are bias and root imply squared error.
For example, for the 2020 Census, the United States Census Bureau introduced the next utility measures and the way they outlined them:
- imply absolute error,
- imply numeric error,
- root imply squared error,
- imply absolute p.c error,
- coefficient of variation,
- whole absolute error of shares, and
- p.c distinction thresholds equaling the depend of absolute p.c distinction above a sure threshold
Imply absolute error, for instance, is the “common absolute worth of the depend distinction for a selected statistic” and is calculated as absolutely the worth of the distinction between the anonymized information and the confidential information outcomes. These measures are averaged throughout geographies, as a result of most information practitioners need these values at sure geographies, corresponding to census-tracts.
End result-Particular Analyses
Privateness researchers ought to then ask the info customers what analyses they sometimes implement as one other measure for information high quality. The concept is information customers ought to make an identical choices regardless if the evaluation output got here from the altered information or confidential information. The privateness neighborhood refers to such a utility measure as an outcome-specific metric.
As an illustration, many public coverage analysis establishments, such because the City Institute, implement microsimulation fashions to find out how new tax coverage plans will have an effect on Individuals. These fashions first estimate a baseline from present financial situations in the USA after which calculate a counter factual or another estimation based mostly on the proposed coverage program change. The distinction between the baseline and the counterfactual estimates reveals the influence of the general public coverage program.
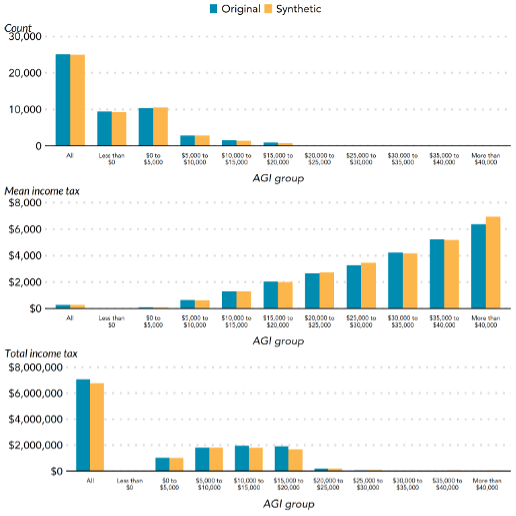
In 2020, the City Institute partnered with the Statistics of Earnings Division on the Inner Income Companies to create a artificial dataset (i.e., pseudo data which are statistically consultant of the unique information) and applied a tax microsimulation mannequin to judge the standard of the artificial file. The mannequin calculated the estimated adjusted gross revenue, private exemptions, deductions, common revenue tax, and tax on long-term capital positive factors and dividends on the confidential and altered information. Determine 1 reveals the outcomes for calculating the adjusted gross revenue, the place the outcomes from the unique and artificial information are shut.
Determine 1. The outcomes for calculating the completely different adjusted gross revenue teams for depend, imply revenue tax, and whole revenue tax based mostly on the unique and artificial tax information from Bowen et al. (2020). AGI stands for adjusted gross revenue.
Equally, in 2021, the City Institute performed an in depth feasibility research on a number of differentially non-public strategies for releasing tabular statistics, imply and quantile statistics, and regression analyses with cross-sectional information. They targeted on these kinds of analyses based mostly on casual interviews with a number of tax consultants. Additionally from these interviews, they evaluated the differentially non-public strategies based mostly on their influence on analyses for making public coverage choices. Lastly, the authors famous which strategies labored in idea with particular situations, however would run into points in follow when consulting the tax consultants.
Marginal Distributional Metrics
One other strategy is to measure the distributional distance between the unique and altered information. Some privateness researchers apply the Chi-square take a look at for categorical variables and the Kolmogorov-Smirnov take a look at for steady variables. For example, Bowen and Snoke (2021) in contrast a number of differentially non-public artificial information for the 2018 Differential Privateness Artificial Knowledge Problem. Particularly, the authors reported the p-value as a scale-free distance measure relatively than the normal null speculation significance testing, the place a better p-value signifies a better utility. This adjustment permits researchers to check the unique and differentially non-public artificial information that had completely different variety of observations and variables with completely different scaling.
World Utility Metrics
Utilizing world utility metrics or discriminant-based algorithms is one other solution to consider information high quality that is rising in popularity in literature however will not be generally used or adopted by any federal company (so far as this creator is conscious of). The worldwide utility metrics try to measure how shut or related the anonymized information are to the confidential information.
A easy instance can be evaluating two anonymized, training datasets, one with 10 p.c of data which have “lower than highschool” training and one with 13 p.c, the place the previous is nearer to the confidential information worth of 9 p.c. Most world utility metrics evaluate in opposition to a number of variables relatively than one or two.
At a excessive degree, world utility metrics first mix the confidential information with the publicly launched information and mark every file as being from the confidential information or the anonymized, public information. Subsequent, the privateness researcher should determine what classification mannequin to make use of to discern whether or not a file is from the confidential or the anonymized information. If the classification mannequin “struggles” to assign a file to both the confidential or public information, privateness researchers assume that the 2 datasets are related. Extra particularly, every file receives a chance of being labeled as being from the confidential information or the general public information. A chance near 50 p.c means the classification mannequin can’t predict any higher than a coin flip.
Lastly, relying on the worldwide utility measure, the strategy distills these possibilities right into a single worth or a number of values to convey how related the launched information are to the unique information. The “accuracy” will depend on what classification mannequin privateness consultants use, as a result of every classification mannequin will measure completely different traits of the info. Privateness researchers must conduct extra scientific research to totally perceive these variations. In addition they must discover the way to make these strategies extra computationally environment friendly for the typical information consumer.
Software program Instruments
What about code to implement these utility measures? Sadly, only a few software program instruments exist to implement these utility metrics. One is synthpop, an R package deal that makes artificial information of individual-level information that has some utility metrics, corresponding to a worldwide utility metric referred to as pMSE-ratio. The privateness researchers that performed further utility metrics for the 2018 NIST Differential Privateness Artificial Knowledge Problem posted their open-source code on GitHub, however are removed from being sturdy, software program high quality code. Regardless that there’s a demand for higher utility metric software program, a few of the problem in creating these instruments is little funding and time to assist such a work.
Takeaway
It’s unattainable for privateness researchers and information practitioners to make sure the launched information and statistics will present legitimate outcomes for all analyses. Because of this they apply a set of utility metrics to evaluate the standard of the differentially non-public information and statistics. In addition they attempt to concentrate on just a few key analyses based mostly on information consumer wants, to realize a extra informative analysis on the info high quality and usefulness. These steps and fixed conversations with information practitioners are obligatory as a result of there isn’t any “one-size-fits-all”.
Coming Up Subsequent
On this put up we mentioned quite a few utility metrics for differential privateness which will be utilized in a wide range of use circumstances. Within the subsequent put up we are going to flip our consideration again to a selected use case: differentially non-public machine studying.
This put up is a part of a collection on differential privateness. Study extra and browse all of the posts printed to this point on the differential privateness weblog collection web page in NIST’s Privateness Engineering Collaboration Area.
[ad_2]
Source link







{kind=link}