

[ad_1]

Credit score:
metamorworks/shutterstock.com
We’re delighted to introduce the ultimate visitor authors in our weblog sequence, Nicolas Papernot and Abhradeep Thakurta, analysis scientists at Google Mind, whose analysis explores purposes of differential privateness to machine studying. – Joseph Close to and David Darais
Earlier posts on this sequence have explored differential privateness for conventional knowledge analytics duties, corresponding to combination queries over database tables. What if we need to use state-of-the-art methods like machine studying? Can we obtain differential privateness for these duties, too?
Machine studying is more and more getting used for delicate duties like medical prognosis. On this context, we wish to make sure that machine studying algorithms don’t memorize delicate details about the coaching set, corresponding to the precise medical histories of particular person sufferers. As we’ll see on this put up, differentially non-public machine studying algorithms can be utilized to quantify and sure leakage of personal data from the learner’s coaching knowledge. Particularly, it permits us to forestall memorization and responsibly practice fashions on delicate knowledge.
Why do we’d like non-public machine studying algorithms?
Machine studying algorithms work by learning a number of knowledge and updating the mannequin’s parameters to encode the relationships in that knowledge. Ideally, we want the parameters of those machine studying fashions to encode common patterns (e.g., ‘‘sufferers who smoke usually tend to have coronary heart illness’’) relatively than information about particular coaching examples (e.g., “Jane Smith has coronary heart illness”).
Sadly, machine studying algorithms don’t study to disregard these specifics by default. If we need to use machine studying to resolve an necessary job, like making a most cancers prognosis mannequin, then once we publish that machine studying mannequin we would additionally inadvertently reveal details about the coaching set.
A standard false impression is that if a mannequin generalizes (i.e., performs nicely on the check examples), then it preserves privateness. As talked about earlier, that is removed from being true. One of many essential causes being that generalization is a median case conduct of a mannequin (over the distribution of information samples), whereas privateness should be offered for everybody, together with outliers (which can deviate from our distributional assumptions).
Over time, researchers have proposed numerous approaches in direction of defending privateness in studying algorithms (k-anonymity [SS98], l-diversity [MKG07], m-invariance [XT07], t-closeness [LLV07] and so forth.). Sadly, [GKS08] all these approaches are weak to so-called composition assaults, which use auxiliary data to violate the privateness safety. Famously, this technique allowed researchers to de-anonymize a part of a film scores dataset launched to members of the Netflix Prize when the people had additionally shared their film scores publicly on the Web Film Database (IMDb) [NS08].
Differential privateness helps design higher machine studying algorithms
Now we have seen in earlier posts that the noise required to attain differential privateness can cut back the accuracy of the outcomes. Current analysis has proven, counterintuitively, that differential privateness can enhance generalization in machine studying algorithms – in different phrases, differential privateness could make the algorithm work higher! [DFH15] formally confirmed that generalization for any DP studying algorithm comes without cost. Extra concretely, if a DP studying algorithm has good coaching accuracy, it’s assured to have good check accuracy.
That is true as a result of differential privateness itself acts as a really sturdy type of regularization.
Non-public Algorithms for Coaching Deep Studying Fashions
We now describe two approaches for coaching deep neural networks with differential privateness. The primary, known as DP-SGD, provides noise to every gradient computed by SGD to make sure privateness. The second, known as Mannequin Agnostic Non-public Studying, trains many (non-private) fashions on subsets of the delicate knowledge and makes use of a differentially non-public mechanism to combination the outcomes.
DP-SGD
The primary method, on account of SCS13, BST14, and ACG16, is known as differentially non-public stochastic gradient descent (DP-SGD). It proposes to change the mannequin updates computed by the commonest optimizer utilized in deep studying: stochastic gradient descent (SGD).
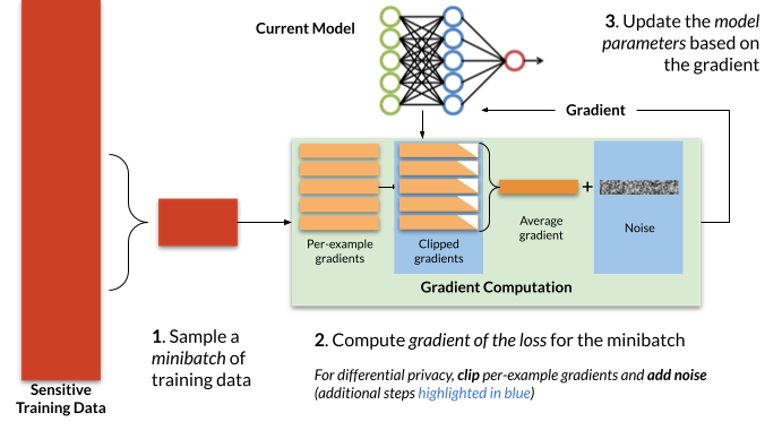
Determine 1: Stochastic Gradient Descent (SGD) and Differentially Non-public SGD (DP-SGD). To attain differential privateness, DP-SGD clips and provides noise to the gradients, computed on a per-example foundation, earlier than updating the mannequin parameters. Steps required for DP-SGD are highlighted in blue; non-private SGD omits these steps.
Sometimes, stochastic gradient descent trains iteratively, repeatedly making use of the method depicted in Determine 1. At every iteration, a small variety of coaching examples (a “minibatch”) are sampled from the coaching set. The optimizer computes the common mannequin error on these examples, after which differentiates this common error with respect to every of the mannequin parameters to acquire a gradient vector. Lastly, the mannequin parameters (θt) are up to date by subtracting this gradient (∇t) multiplied by a small fixed η (the studying charge, which controls how rapidly the optimizer updates the mannequin’s parameters).
At a excessive stage, two modifications are made by DP-SGD to acquire differential privateness: gradients, that are computed on a per-example foundation (relatively than averaged over a number of examples), are first clipped to regulate their sensitivity, and, second, spherical Gaussian noise bt is added to their sum to acquire the indistinguishability wanted for DP. Succinctly, the replace step may be written as follows:
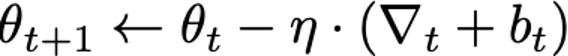
Three essential parts within the above DP-SGD algorithm that distinguishes itself from conventional SGD are: i) per-example clipping and ii) Gaussian noise addition. As well as, for the evaluation to carry, DP-SGD requires that sub-sampling of mini batches is uniform at random from the coaching knowledge set. Whereas this isn’t a requirement of DP-SGD per se, in observe many implementations of SGD don’t fulfill this requirement and as a substitute analyze totally different permutations of the information at every epoch of coaching.
For a hard and fast DP assure, the magnitude of the Gaussian noise that will get added to the gradient updates in every step in DP-SGD is proportional to the variety of steps the mannequin is educated for. Because of this, you will need to tune the variety of coaching steps for greatest privateness/utility trade-offs.
For extra data on DP-SGD, take a look at this tutorial, which supplies a small code snippet to coach a mannequin with DP-SGD.
Mannequin Agnostic Non-public Studying
DP-SGD provides noise to the gradient throughout mannequin coaching, which may harm accuracy. Can we do higher? Mannequin agnostic non-public studying takes a distinct method, and in some instances achieves higher accuracy for a similar stage of privateness when in comparison with DP-SGD.
Mannequin agnostic non-public studying leverages the Pattern and Mixture framework [NRS07], a generic methodology so as to add differential privateness to a non-private algorithm with out caring concerning the inside workings of it (therefore the time period, mannequin agnostic). Within the context of machine studying, one can state the primary thought as follows: Take into account a multi-class classification downside. Take the coaching knowledge, and cut up into ok disjoint subsets of equal measurement. Practice impartial fashions θ1, …, θok on the disjoint subsets. To be able to predict on an check instance x, first, compute a non-public histogram over the set of ok predictions θ1(x), …, θok(x). Then, choose and output the bin within the histogram primarily based on the best rely, after including a small quantity of Laplace/Gaussian noise to the counts.
Within the context of DP studying, this explicit method was utilized in two totally different traces of labor: i) PATE [PAE16], and ii) Mannequin agnostic non-public studying [BTT18]. Whereas the latter focussed on acquiring theoretical privateness/utility trade-offs for a category of studying duties (e.g., agnostic PAC studying), the PATE method focuses on sensible deployment. Each these traces of labor make one widespread remark. If the predictions from θ1(x), …, θok(x) are pretty constant, then the privateness price by way of DP could be very small. Therefore, one can run numerous prediction queries, with out violating DP constraints. Within the following, we describe the PATE method intimately.
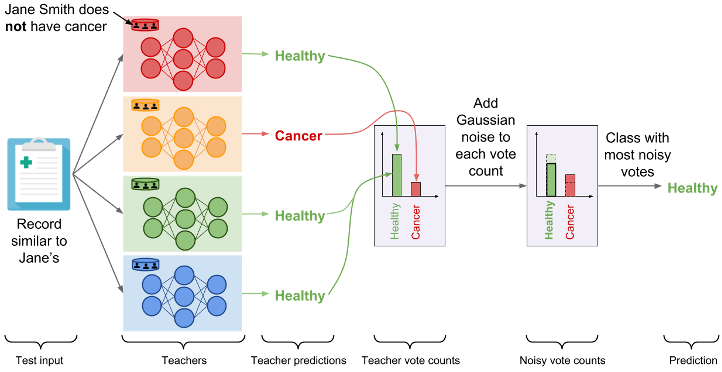
Determine 2: The PATE framework. Quite than including noise to gradients, PATE as a substitute trains many non-private fashions (the “Lecturers”) on subsets of the information, then asks the fashions to “vote” on the proper prediction utilizing a differentially non-public aggregation mechanism. (from cleverhans.io – reproduced with permission)
The non-public aggregation of instructor ensembles (PATE) proposes to have an ensemble of fashions educated with out privateness predict with differential privateness by having these fashions predict in combination relatively than revealing their particular person predictions. The ensemble of fashions is obtained by partitioning a non-public dataset into (non-overlapping) smaller subsets of information. Their predictions are then aggregated utilizing the non-public histogram method described above: the label predicted is the one whose noisy rely of votes is the biggest. The random noise added to vote counts prevents the end result of aggregation from reflecting the votes of any particular person lecturers to guard privateness. When consensus is sufficiently sturdy among the many ensemble of fashions, the noise doesn’t alter the output of the aggregation.
Sensible Deployment & Software program Instruments
The 2 approaches we launched have the benefit of being conceptually easy to know. Fortuitously, there additionally exist a number of open-source implementations of those approaches. As an example, DP-SGD is carried out in TensorFlow Privateness, Objax, and Opacus. Which means that one is ready to take an current TensorFlow, JAX, or PyTorch pipeline for coaching a machine studying mannequin and substitute a non-private optimizer with DP-SGD. An instance implementation of PATE can be accessible in TensorFlow Privateness. So what are the concrete potential obstacles to deploying machine studying with differential privateness?
The primary impediment is the accuracy of privacy-preserving fashions. Datasets are sometimes sampled from distribution with heavy tails. As an example, in a medical software, there are sometimes (and fortuitously) fewer sufferers with a given medical situation than sufferers with out that situation. Which means that there are fewer coaching examples for sufferers with every medical situation to study from. As a result of differential privateness prevents us from studying patterns which aren’t discovered typically throughout the coaching knowledge, it limits our means to study from these sufferers for which now we have only a few examples of [SPG]. Extra typically, there’s usually a trade-off between the accuracy of a mannequin and the power of the differential privateness assure it was educated with: the smaller the privateness finances is, the bigger the impression on accuracy sometimes is. That stated, this stress shouldn’t be at all times inevitable and there are situations the place privateness and accuracy are synergical as a result of differential privateness implies generalization [DFH15] (however not vice versa).
The second impediment to deploying differentially non-public machine studying may be the computational overhead. As an example, in DP-SGD one should compute per-example gradients relatively than common gradients. This usually implies that optimizations carried out in machine studying frameworks to use matrix algebra supported by underlying {hardware} accelerators (e.g., GPUs) are tougher to make the most of. In one other instance, PATE requires that one practice a number of fashions (the lecturers) relatively than a single mannequin so this could additionally introduce overhead within the coaching process. Fortuitously, this price is generally mitigated in latest implementations of personal studying algorithms, particularly in Objax and Opacus.
The third impediment to deploying differential privateness, in machine studying however extra typically in any type of knowledge evaluation, is the selection of privateness finances. The smaller the finances, the stronger the assure is. This implies one can evaluate two analyses and say which one is “extra non-public”. Nevertheless, this additionally implies that it’s unclear what’s “sufficiently small” of a privateness finances. That is significantly problematic provided that purposes of differential privateness to machine studying usually require a privateness finances that gives little theoretical ensures to be able to practice a mannequin whose accuracy is giant sufficient to warrant a helpful deployment. Thus, it could be attention-grabbing for practitioners to judge the privateness of their machine studying algorithm by attacking it themselves. Whereas the theoretical evaluation of an algorithm’s differential privateness ensures supplies a worst-case assure limiting how a lot non-public data the algorithm can leak in opposition to any adversary, implementing a selected assault may be helpful to understand how profitable a specific adversary could be. This helps interpret the theoretical assure however ought to under no circumstances be seen as an alternative to it. Open-source implementations of such assaults are more and more accessible: e.g., for membership inference.
Conclusion
Within the above, we mentioned a few of the algorithmic approaches in direction of differentially non-public mannequin coaching which have been efficient each in theoretical and sensible settings. Since it’s a quickly rising discipline, we couldn’t cowl many necessary elements of the analysis house. Some outstanding ones embrace: i) Alternative of the perfect hyperparameters within the coaching of DP fashions: To be able to make sure that the general algorithm preserves differential privateness, one wants to make sure that the selection of hyperparameters itself preserves DP. Current analysis has offered algorithms for a similar [LT19]. ii) Alternative of community structure: It’s not at all times true that the perfect identified mannequin architectures for non-private mannequin coaching are certainly the perfect for coaching with differential privateness. Particularly, we all know that the variety of mannequin parameters could have adversarial results on the privateness/utility trade-offs [BST14]. Therefore, choosing the proper mannequin structure is necessary for offering an excellent privateness/utility trade-off [PTS21], and (iii) Coaching within the federated/distributed setting: Within the above exposition, we assumed that the coaching knowledge lies in a single centralized location. Nevertheless, in settings like Federated Studying (FL), the information data may be extremely distributed, e.g., throughout numerous cell units. Working DP-SGD or PATE model algorithms within the FL settings raises a sequence of challenges, however is usually facilitated by current cryptographic primitives as demonstrated within the case of PATE by the CaPC protocol [CDD21], or by distributed non-public studying algorithms designed particular to FL settings [BKMTT20,KMSTTZ21]. It’s an lively space of analysis to handle all the above challenges.
Acknowledgements
The authors wish to thank Peter Kairouz, Brendan McMahan, Ravi Kumar, Thomas Steinke, Andreas Terzis, and Sergei Vassilvitskii for detailed suggestions and edit options. Elements of this weblog put up beforehand appeared on www.cleverhans.io
Coming Up Subsequent
This put up is our final to discover new strategies in differential privateness, and practically concludes our weblog sequence. Keep tuned for a last put up the place we’ll summarize the subjects lined on this sequence, wrap up with some last ideas, and share how we envision this undertaking to reside on after the weblog.
This put up is a part of a sequence on differential privateness. Study extra and browse all of the posts printed thus far on the differential privateness weblog sequence web page in NIST’s Privateness Engineering Collaboration Area.
[ad_2]
Source link







{kind=link}