

[ad_1]

Credit score:
metamorworks/shutterstock.com
On this collection, we have examined a number of alternative ways to reply queries over information utilizing differential privateness. Up to now every method requires altering the best way we reply queries – normally by including noise to the reply – and modifying the instruments we might usually use for analyzing information.
What if we need to use current information evaluation instruments, however nonetheless defend privateness? For instance, the advertising division of our pumpkin spice latte firm could be accustomed to exporting gross sales information to a spreadsheet on the finish of every month to research gross sales tendencies utilizing a well-liked spreadsheet software. They want to higher defend people’ privateness, however don’t need to learn–or buy–new instruments.
One method is to provide a “de-identified” or “anonymized” model of the info to be used by the advertising division. This information seems like the unique dataset, however figuring out info is redacted. This anonymized information can then be analyzed utilizing any device the advertising division likes. Sadly, as described in our first publish, this method doesn’t stop re-identification of people.
Can we obtain the identical workflow, besides use differential privateness to raised defend privateness? The reply is “sure”: utilizing strategies for producing differentially personal artificial information. A differentially personal artificial dataset seems like the unique dataset – it has the identical schema and makes an attempt to take care of properties of the unique dataset (e.g., correlations between attributes) – but it surely offers a provable privateness assure for people within the unique dataset.
It is vital to notice that many strategies for producing artificial information don’t fulfill differential privateness (or any privateness property). These strategies could supply some partial privateness safety, however they don’t give the identical safety backed by mathematical proof as differentially personal artificial information does.
Use Instances & Utility
Differentially personal artificial information has an enormous benefit over different approaches for personal information evaluation: as proven in Determine 1, it permits analysts to make use of any device or workflow to course of the info. As soon as the info has been “privatized,” no additional safety is required. The differentially personal artificial information could also be analyzed, shared, and mixed with different datasets, with no extra threat to privateness. This property makes differentially personal artificial information a lot simpler to make use of than the approaches we now have mentioned previously–all of which require modifying the instruments and workflows used to research information.
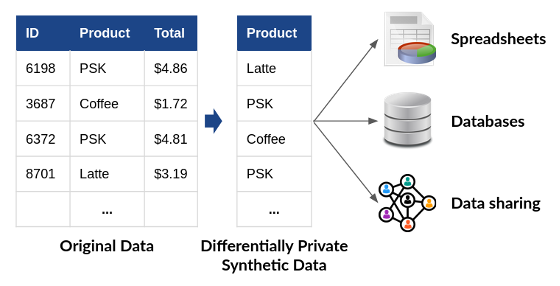
Determine 1: Makes use of of differentially personal artificial information. Downstream customers of the info needn’t be privacy-aware! (PSK = Pumpkin Spice Latte)
The first problem of differentially personal artificial information is accuracy. Developing correct differentially personal artificial information seems to be extraordinarily difficult in follow. As a rule of thumb, a purpose-built differentially personal evaluation, like those described in earlier posts, will usually yield higher accuracy than the identical evaluation on artificial information. Nevertheless, instruments for this objective are growing quickly. In 2018, NIST carried out a Differential Privateness Artificial Information Problem, which attracted submissions based mostly on many alternative strategies. For the benchmark issues thought of within the Problem, the top-scoring options produced extraordinarily correct differentially personal artificial information. Extra on these options later within the publish.
However, a excessive diploma of accuracy will not be important for each use case. Typically tough accuracy is sufficient to offer you the insights and tendencies that you want to meet your goals. Differentially personal artificial information might be a superb answer in these eventualities.
Producing Artificial Information
Conceptually, all strategies for producing artificial data–privacy-preserving or not–start by constructing a probabilistic mannequin of the underlying inhabitants from which the unique information was sampled. Then, this mannequin is used to generate new information. If the mannequin is an correct illustration of the inhabitants, then the newly generated information will retain all of the properties of that inhabitants, however every generated information level will symbolize a “faux” particular person who does not truly exist.
Constructing the mannequin is essentially the most difficult a part of this course of. Many strategies have been developed for this objective, from easy approaches based mostly on counting to complicated ones based mostly on deep studying. The submissions to NIST’s Differential Privateness Artificial Information Problem spanned the spectrum of those strategies; the highest 5 scoring algorithms on this problem have been launched as open-source software program, and can be found on the NIST Privateness Engineering Collaboration House. The remainder of this publish will describe the concepts behind two of those approaches.
Software program Instruments: Marginal Distributions
Think about that we might prefer to generate artificial gross sales information for our pumpkin spice latte firm. One method to accomplish that is utilizing a differentially personal marginal distribution, as in Determine 2. From the unique tabular information, we assemble a histogram by counting the variety of every drink offered. Subsequent, we add noise to the histogram to fulfill differential privateness. Lastly, we divide every noisy rely by the whole to find out what proportion of all drinks have been of the particular sort. This closing step produces a one-way marginal distribution – it considers just one attribute of the unique information and ignores correlations between attributes.
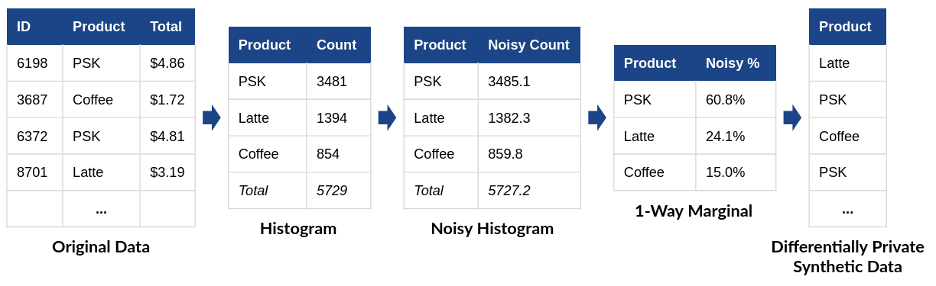
Determine 2: Producing a differentially personal artificial information utilizing a marginal distribution.
(PSK = Pumpkin Spice Latte)
Now, we are able to use the one-way marginal to generate a “faux buy” utilizing weighted randomness. We choose a drink sort at random – however with the randomness weighted based on the one-way marginal we now have generated. Within the instance in Determine 1, 60.8% of the generated purchases needs to be pumpkin spice lattes, 24.1% needs to be lattes, and 15.0% needs to be common coffees.
Marginal distributions kind the idea for a lot of differentially personal artificial information algorithms, together with the top-scoring algorithm from the 2018 NIST Problem. The main problem of this method is available in preserving correlations between information attributes. For instance, our gross sales information may embrace the shopper’s age along with the drink sort – and age could be extremely correlated with drink sort (youthful clients, we would think about, usually tend to buy pumpkin spice lattes than different drink varieties). We are able to repeat the method used above on each information attributes individually – however that method doesn’t seize the correlation that was current between the 2.
We are able to protect this correlation by calculating a two-way marginal – a distribution over each information attributes concurrently. However this marginal has many extra attainable choices (the entire attainable combos of age and drink sort), and it’ll lead to a weaker “sign” relative to the noise for every choice.
Preserving correlations like these requires a cautious steadiness between the marginals being measured and the energy of the sign being preserved. The profitable algorithm within the 2018 Problem, submitted by Ryan McKenna, makes use of a differentially personal algorithm to detect correlations within the information, after which measures 3-way marginals that embrace correlated attributes. This method ensures that correlations are preserved, whereas sustaining a excessive sign energy. The second, third, and fourth place finishes within the Problem additionally used an method based mostly on marginal distributions.
Software program Instruments: Deep Studying
One other method to construct a mannequin of the underlying inhabitants from the unique information is with machine studying strategies. Up to now a number of years, deep learning-based strategies for producing artificial information have develop into extraordinarily succesful in some domains. For instance, thispersondoesnotexist.com makes use of a Generative Adversarial Community (GAN) – a kind of neural community for deep studying – to generate convincing pictures of imaginary folks. The identical method can be utilized to generate artificial information in different domains – like our latte gross sales information, for instance – by coaching the neural community on unique information from the best area.
To guard the privateness of people within the unique information, we are able to prepare the neural community utilizing a differentially personal algorithm. As we are going to talk about in a later publish, a number of algorithms have been proposed for this objective, and open-source implementations for well-liked deep studying frameworks have applied these algorithms (e.g., TensorFlow Privateness and Opacus). If the neural community modeling the underlying inhabitants is educated with differential privateness, then by the post-processing property, the artificial information it generates additionally satisfies differential privateness.
A GAN-based method was used within the fifth-place submission to the 2018 NIST Problem, submitted by a crew from the College of California, Los Angeles. Usually, deep learning-based approaches for differentially personal artificial information are much less correct than the marginal-based approaches mentioned within the final part for low-dimensional tabular information (like the info in our latte instance). Nevertheless, that is an lively space of analysis, and approaches based mostly on deep studying could show extraordinarily efficient for high-dimensional information (e.g., photographs, audio, video).
Coming Up Subsequent
Up to now, this collection has centered on how differential privateness works and apply differential privateness to reply attention-grabbing questions on information. Nevertheless, implementation of differential privateness alone will not be sufficient to guard privateness – it must be applied accurately. This correctness might be arduous to attain as a result of differential privateness is applied in software program, and all software program is liable to implementation bugs. It is a specific problem as a result of buggy differentially personal applications do not crash – as a substitute, they silently violate privateness in methods that may be arduous to detect. Our subsequent publish will talk about instruments and strategies which might be certain that differential privateness is applied accurately in a selected software, in addition to the constraints of conventional approaches to software program assurance within the context of differential privateness.
This publish is a part of a collection on differential privateness. Study extra and browse all of the posts revealed so far on the differential privateness weblog collection web page in NIST’s Privateness Engineering Collaboration House.
[ad_2]
Source link






{kind=link}